从沙粒到城市:FPGA 芯片的六级架构层次
💡 在上一篇文章中,我们”拆开”了一颗 FPGA,认识了 CLB、IOB、Block RAM、DSP 这些内部资源。但如果你打开 Vivado 的 Device View,放大再放大,你会发现一个问题:
CLB 里面还有 Slice,Slice 里面还有 LUT 和 FF……这些东西到底是怎么一层一层组织起来的?
这篇文章会带你从 FPGA 芯片最微小的”沙粒”——BEL,一路向上看到整颗芯片 Device,理解 Xilinx FPGA 的六级层次化架构。搞懂这套”俄罗斯套娃”,你在 Vivado 里看到的每一个名字、每一个坐标都会变得有意义。
目录
- 1. 为什么要了解芯片架构层次?
- 2. 六级层次总览:从沙粒到城市
- 3. BEL:不可再分的原子积木
- 4. Site:装满积木的标准房间
- 5. Tile:铺满地砖的街区
- 6. Clock Region:时钟管辖的行政区
- 7. SLR:多芯片拼接的超级区域
- 8. Device:整颗芯片
- 9. 在 Vivado 中亲眼看到这些层次
- 10. 总结
- 常见问题
- 参考资料
1. 为什么要了解芯片架构层次?
你可能会想:“我写 Verilog 就行了,为什么要关心芯片内部怎么组织的?”
三个实际场景告诉你答案:
- 看懂综合报告:当 Vivado 告诉你”设计使用了 1200 个 Slice、4800 个 LUT”,你需要知道 Slice 和 LUT 是什么关系,才能判断资源是否紧张
- 理解时序约束:当你遇到跨时钟域的时序违例,理解 Clock Region 的边界能帮你定位问题
- 调试布局布线:当你在 Device View 里看到
SLICE_X12Y34、BRAM_X2Y5这样的坐标,理解层次结构才能快速定位资源位置
💡 工程师手记:我第一次在 Vivado 里看到
SLICE_X0Y0这个名字时,完全不知道 X 和 Y 代表什么。后来理解了 FPGA 的层次化命名规则,才发现这套坐标系统非常精确——每个资源都有唯一的”门牌号”,就像城市里的街道地址一样。
2. 六级层次总览:从沙粒到城市
Xilinx FPGA 的内部架构采用自底向上的层次化设计,从最小的功能单元到整颗芯片,共分为六级:
BEL(基本逻辑单元)
→ Site(站点 = BEL 的集合)
→ Tile(瓦片 = Site 的集合)
→ Clock Region(时钟区域 = Tile 的集合)
→ SLR(超级逻辑区域 = Clock Region 的集合)
→ Device(整颗芯片 = SLR 的集合)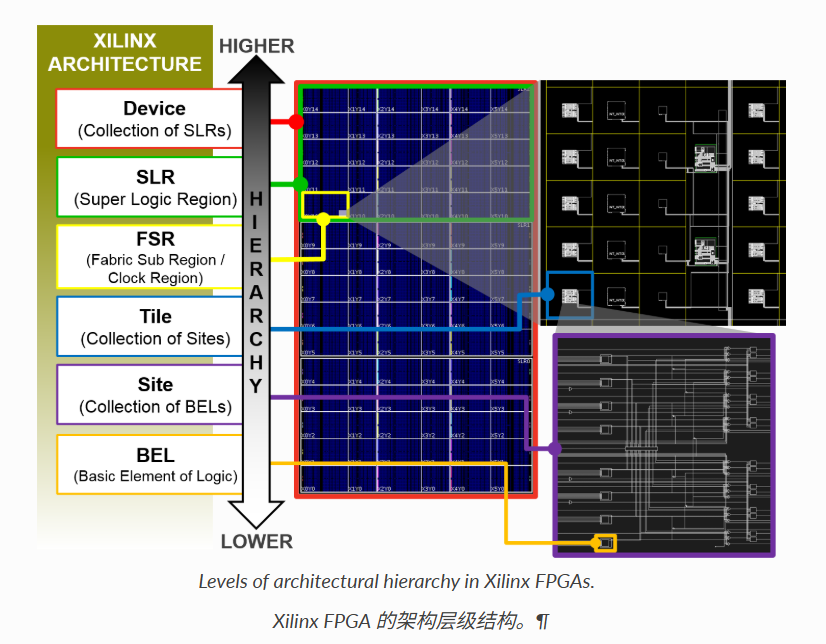
用一个城市类比来理解:
| 层级 | FPGA 概念 | 城市类比 | 关键特征 |
|---|---|---|---|
| 第 1 级 | BEL | 一块砖 | 最小功能单元,不可再分 |
| 第 2 级 | Site | 一个房间 | 容纳特定类型的 BEL |
| 第 3 级 | Tile | 一栋楼 | 包含多个房间 + 楼内走廊 |
| 第 4 级 | Clock Region | 一个街区 | 共享同一套市政管网(时钟网络) |
| 第 5 级 | SLR | 一个城区 | 独立的硅片 Die |
| 第 6 级 | Device | 整座城市 | 完整的 FPGA 芯片 |
接下来我们逐层拆解。
3. BEL:不可再分的原子积木
BEL(Basic Element of Logic,基本逻辑单元) 是 FPGA 中最底层、不可再分的功能单元。即使你没有加载任何设计,在 Vivado 的 Device View 中也能看到它们——因为它们是物理上固化在硅片上的。
BEL 的三种类型
| 类型 | 作用 | 举例 |
|---|---|---|
| 逻辑 BEL | 实现设计中的逻辑功能 | LUT、FF、Carry Chain |
| 路由 BEL | 在 BEL 之间传输信号 | FFMUX、DOUTMUX |
| 站点端口 BEL | 连接 Site 内部与外部信号 | 输入/输出接口引脚 |
逻辑 BEL 是你最常打交道的——你写的每一行 Verilog 代码,最终都会被 Vivado 的 place_design 命令映射到某个具体的逻辑 BEL 上。
路由 BEL 则是”幕后英雄”。它们不承载任何设计逻辑,但负责在逻辑 BEL 之间选择信号路径。比如 FFMUX 决定触发器的输入是来自 LUT 输出还是旁路输入。
💬 你可能会问:路由 BEL 和可编程互联资源有什么区别?
路由 BEL 是 Site 内部的信号选择器,作用范围很小;可编程互联资源(Switch Box、Connection Block)是 Site 之间的布线网络,负责跨越更远的距离。两者配合,才能把信号从芯片的一端传到另一端。
4. Site:装满积木的标准房间
Site(站点) 是 BEL 的集合,代表芯片上一个具体的物理位置。你可以把它想象成一个标准化的”房间”,里面按固定规格摆放了特定类型的 BEL。
常见的 Site 类型
| Site 类型 | 内含的 BEL | 对应的功能 |
|---|---|---|
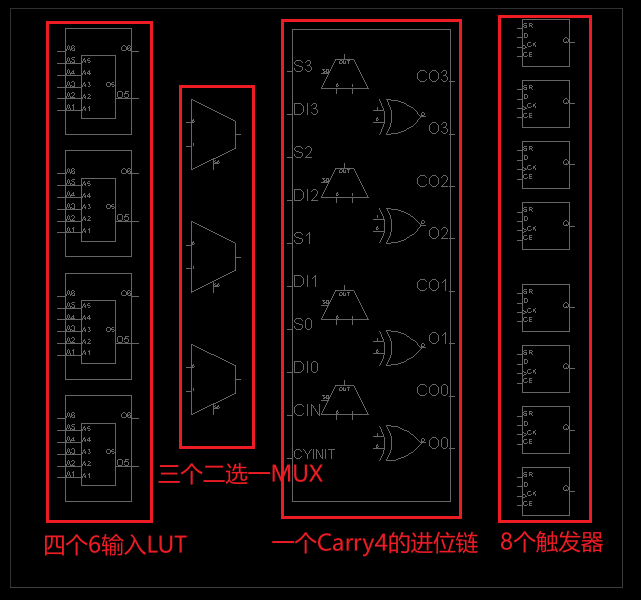
| SLICEL | 4×LUT + 8×FF + Carry Chain + MUX | 通用逻辑 |
| SLICEM | 同 SLICEL + 分布式 RAM/SRL 能力 | 逻辑 + 小型存储 |
| BRAM Site | Block RAM 硬核 | 大容量片上存储 |
| DSP Site | DSP48 硬核 | 乘加运算 |
| IOB Site | I/O 缓冲器 | 芯片引脚接口 |
| MMCM/PLL Site | 时钟管理模块 | 时钟倍频/分频 |
每个 Site 都有一个唯一的名字,格式为 类型_X#Y#。比如 SLICE_X12Y34 表示第 12 列、第 34 行的 Slice。
关键细节:SLICEL 和 SLICEM 共享同一套 XY 坐标网格——这是唯一的例外。其他类型的 Site(如 BRAM、DSP)各自有独立的坐标系。
5. Tile:铺满地砖的街区
Tile(瓦片) 是 Site 的集合,代表 FPGA 结构中一个可重复的基本物理区域块。
如果说 Site 是”房间”,那 Tile 就是”一栋楼”——它不仅包含多个房间(Site),还包含楼内的走廊和电梯(本地互连资源)。
典型的 Tile 组成
| Tile 类型 | 包含的 Site | 附加资源 |
|---|---|---|
| 逻辑 Tile(CLB) | 2 个 Slice(SLICEL/SLICEM) | 开关矩阵(Switch Box) |
| BRAM Tile | BRAM Site | 布线资源 |
| DSP Tile | DSP Site | 布线资源 |
| 互连 Tile(INT) | 无逻辑 Site | 纯开关矩阵 |
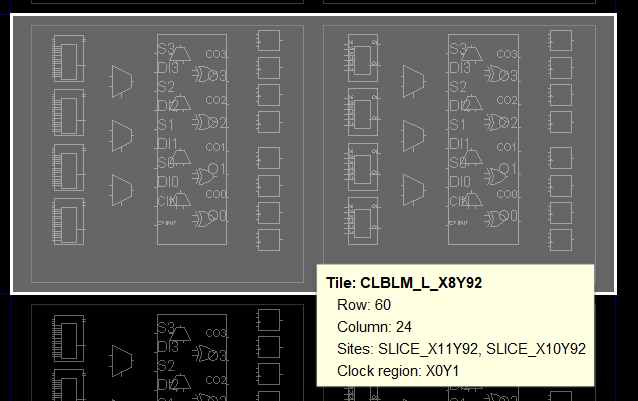
最经典的 Tile 就是 CLB——一个 CLB Tile 包含 2 个 Slice,这也是为什么你经常看到”一个 CLB = 2 个 Slice”的说法。
Tile 之间如何连接?
Tile 本身没有用户可见的引脚。信号通过 Tile 内部的**导线(Wire)传输,导线之间通过PIP(可编程互连点)**连接。当相邻的 Tile 排列在一起时,特定的导线会自动对齐并实现电气连接。
多个 Tile 上的导线可以组成一个节点(Node)——这是跨 Tile 信号传输的基本单位。
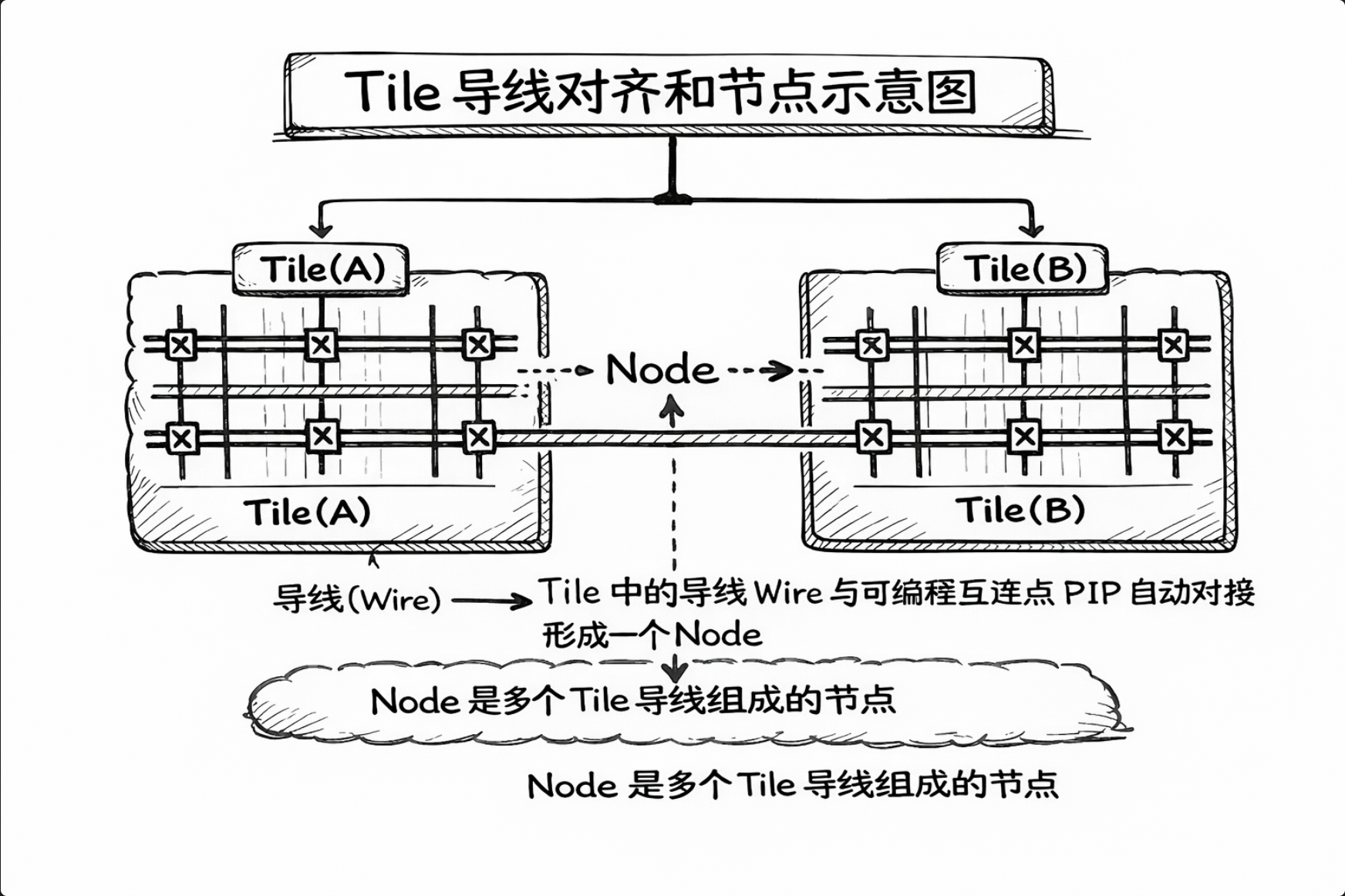
6. Clock Region:时钟管辖的行政区
Clock Region(时钟区域,也叫 FSR) 是由大量 Tile 构成的中等规模物理区域。它最重要的特性是:区域内的所有资源共享同一套时钟分配网络。
为什么要划分时钟区域?
时钟信号是 FPGA 中最特殊的信号——它需要同时驱动成千上万个触发器,而且到达每个触发器的时间差(Clock Skew)必须尽可能小。
把芯片划分成多个时钟区域,每个区域有独立的时钟缓冲器(如 BUFR),可以:
- 降低时钟偏斜:区域内的时钟分配路径更短、更均匀
- 支持多时钟域:不同区域可以使用不同频率的时钟
- 简化布局布线:工具会尽量把同一时钟域的逻辑放在同一个或相邻的 Clock Region 内
⚠️ 设计建议:跨越 Clock Region 边界的信号可能会有额外的布线延迟。如果你的设计有严格的时序要求,尽量让关键路径上的逻辑集中在同一个 Clock Region 内。
💡 工程师手记:我在一个多时钟域设计中遇到过时序违例,排查了很久才发现原因:两个本该在同一时钟域的模块被布局工具分配到了不同的 Clock Region,导致时钟偏斜超出预期。后来通过添加 Pblock 约束,把关键模块限制在同一个 Clock Region 内,时序立刻收敛了。理解 Clock Region 的边界,能帮你在遇到类似问题时少走很多弯路。
一个具体的例子
以 XC7A35T 芯片为例,它有 5 个 I/O Bank,但有 6 个时钟区域——Bank 和时钟区域并不是一一对应的。每个时钟区域覆盖一片矩形的 Tile 阵列,拥有独立的时钟布线轨道。
7. SLR:多芯片拼接的超级区域
💡 如果你使用的是 Artix-7、Spartan-7 等入门级单 Die 芯片,可以跳过本节。SLR 主要影响 Virtex 系列等大型多 Die 器件的设计者。
SLR(Super Logic Region,超级逻辑区域) 是大型 FPGA 特有的概念。
为什么需要 SLR?
当单颗硅片无法容纳足够多的逻辑资源时,Xilinx 使用 SSI(Stacked Silicon Interconnect,堆叠硅互连) 技术,把多颗独立的硅片 Die 并排放在一个硅中介层上,封装成一颗”超大”芯片。
每个 SLR 就是一颗独立的硅片 Die。
| 特性 | 说明 |
|---|---|
| 独立资源 | 每个 SLR 有完整的 CLB、BRAM、DSP、时钟网络 |
| 跨 SLR 连接 | 通过硅中介层上的微凸块(Microbump)互连 |
| 时序影响 | 跨 SLR 信号延迟更大,是时序关键点 |
| 适用器件 | 主要用于 Virtex UltraScale+ 等高端系列 |
💬 你可能会问:我用的是 Artix-7 这样的小芯片,需要关心 SLR 吗?
不需要。单 Die 的 FPGA(如 Artix-7、Kintex-7 的大部分型号)整颗芯片就是一个 SLR,你可以忽略这个层级。SLR 主要影响使用 Virtex 系列大型 FPGA 的设计者。
跨 SLR 设计的注意事项
如果你使用的是多 SLR 器件(比如 xc7v2000t,它有 4 个 SLR),需要注意:
- 高速逻辑尽量约束在同一 SLR 内,避免跨 Die 延迟
- 跨 SLR 的信号走 SLL(Super Long Line,超级长线),带宽和延迟都受限
- Vivado 的资源利用率报告会按 SLR 分别显示,帮你检查资源分布是否均衡
8. Device:整颗芯片
Device 就是整颗 FPGA 芯片——层次结构的最顶层。
每颗 FPGA 芯片由一个唯一的**器件型号(Part Number)**标识,比如 XC7A35T-1CPG236C,这个型号精确定义了:
| 信息 | 示例 | 说明 |
|---|---|---|
| 产品系列 | Artix-7 | 决定架构代次和定位 |
| 逻辑容量 | 35T(约 33,280 个逻辑单元) | CLB/LUT/FF 的总量 |
| 速度等级 | -1 | 数字越大性能越高 |
| 封装 | CPG236 | 引脚数量和封装形式 |
| 温度等级 | C(商业级) | 工作温度范围 |
在 Vivado 中创建工程的第一步就是选择目标 Device——这决定了工具能使用的全部资源、时序模型和约束规则。
9. 在 Vivado 中亲眼看到这些层次
理论讲完了,最好的学习方式是打开 Vivado 亲自看一看。
操作步骤
- 打开一个已实现(Implementation)的工程,进入 Device View
- 缩放到最大:你会看到整颗芯片的全貌——这就是 Device 层级
- 逐步放大:你会依次看到 Clock Region 的边界、Tile 的网格、Site 的轮廓
- 放大到最底层:你能看到 Slice 内部的每一个 LUT、FF、Carry Chain——这就是 BEL 层级
实操示例
下面我们按照上述步骤,在 Vivado 中逐级探索,亲眼看到每一个架构层级。
打开 Device 视图
在 Vivado 中点击 Open Implemented Design,打开实现后的工程,默认进入 Device 界面:
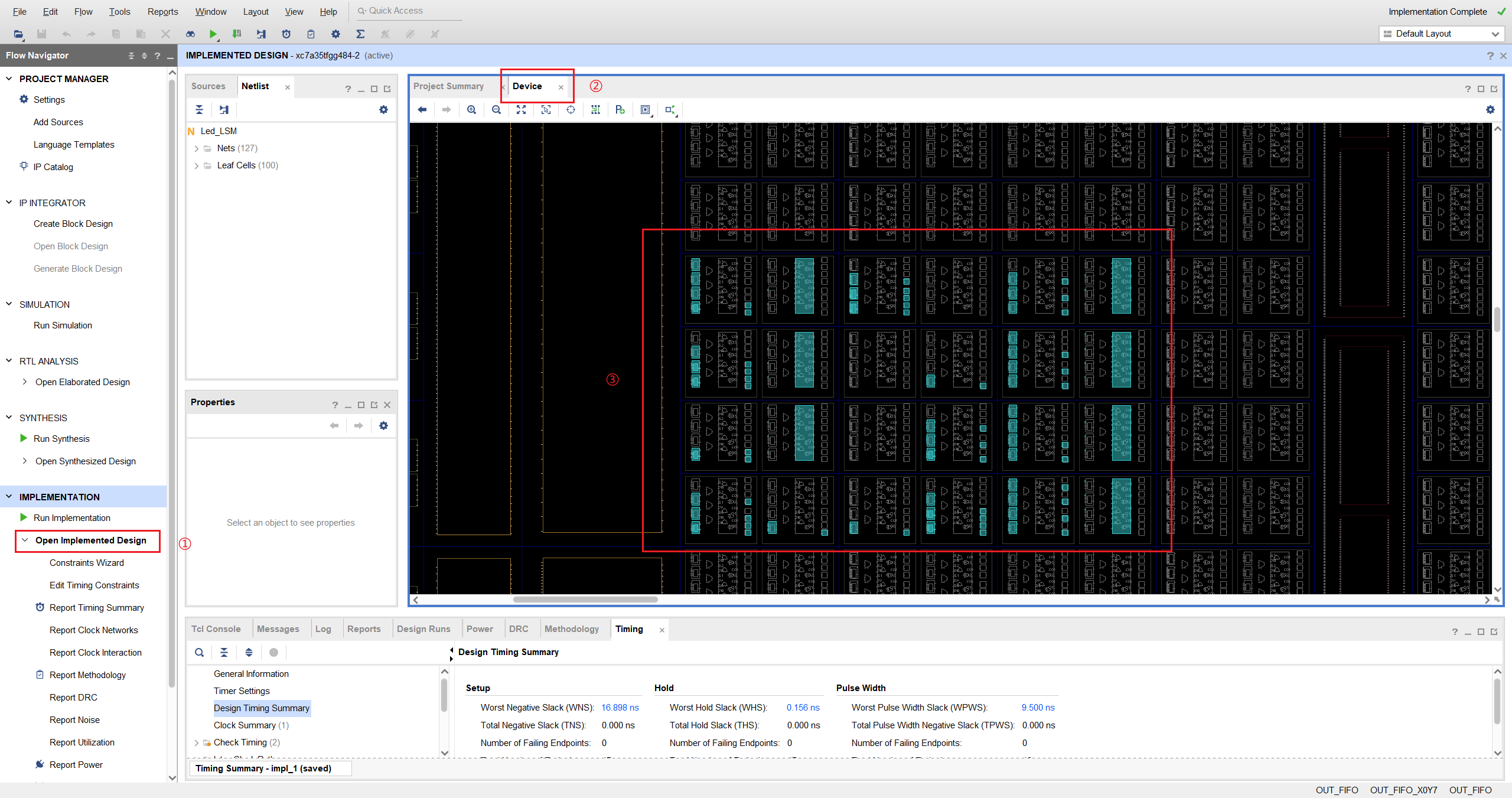
这就是整颗 FPGA 的全貌——Device 层级。接下来我们逐级放大,看看里面装了什么。
SLR:多 Die 器件的顶层结构
如果你使用的是多 SLR 器件(如高端的 xc7v2000tfhg1761-2),在全局视图中可以看到从上到下依次排列着 4 个 SLR,每个 SLR 包含 6 个时钟区域。每个 SLR 本质上是一颗独立的 FPGA,通过 SSI 技术封装在一起:
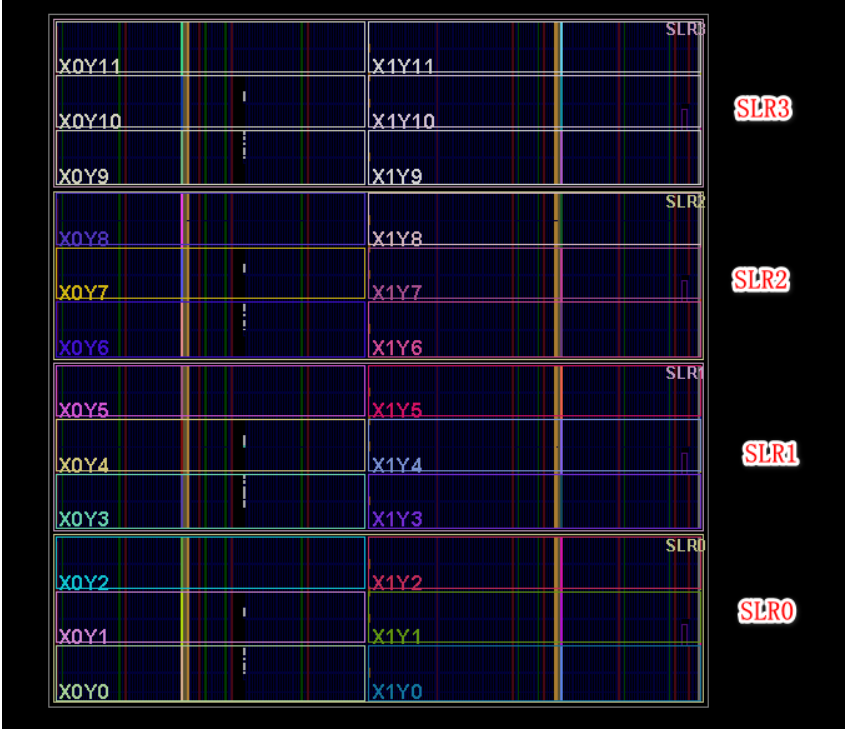
不同 SLR 之间的数据交互需要通过专用的 SLL(Super Long Line,超级长线)布线资源,跨 SLR 的布线成本和延迟都更大:
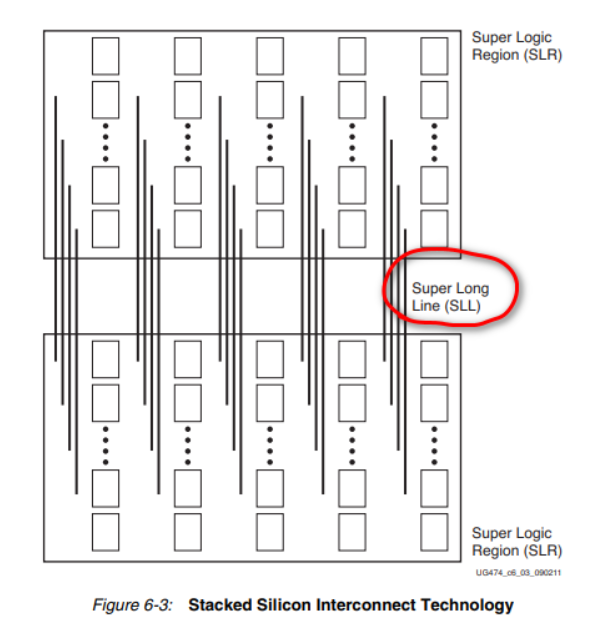
💡 如果你用的是 Artix-7、Spartan-7 等单 Die 芯片,整颗芯片就是一个 SLR,可以跳过这一步。
Clock Region:时钟区域的边界
以单 Die 芯片 XC7A35TFGG484-2 为例,它有 5 个 I/O Bank,但有 6 个时钟区域——两者并非一一对应。在 Device View 中可以清晰看到各时钟区域的划分:
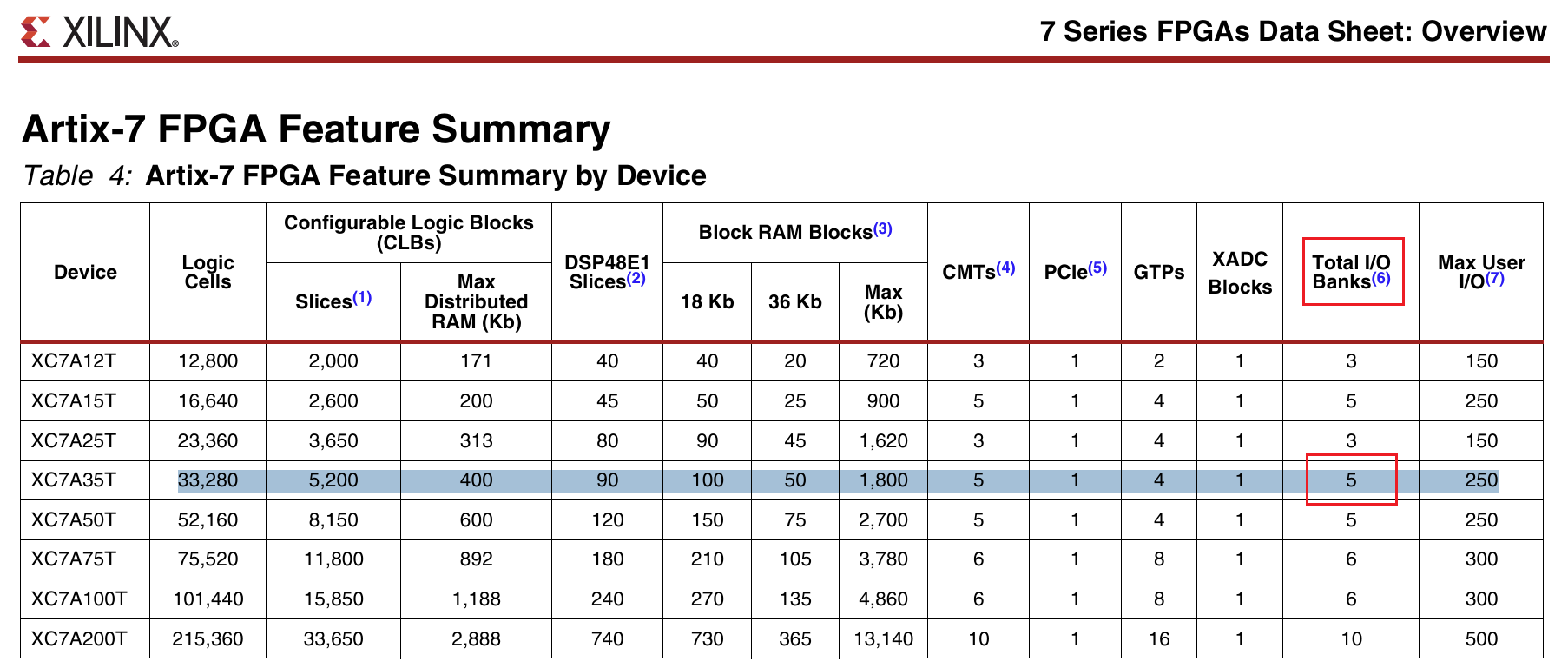
放大后,每个时钟区域内部的资源分布更加清晰:

Tile:网格中的基本单元
继续放大,可以看到 Tile 的网格排列。最经典的 Tile 就是 CLB,每个 CLB 包含 2 个 Slice,同时附带开关矩阵用于跨 Tile 互连。与 Site 类似,每个 Tile 也有独立的坐标标识:
Site:走进 Slice 和硬核 IP
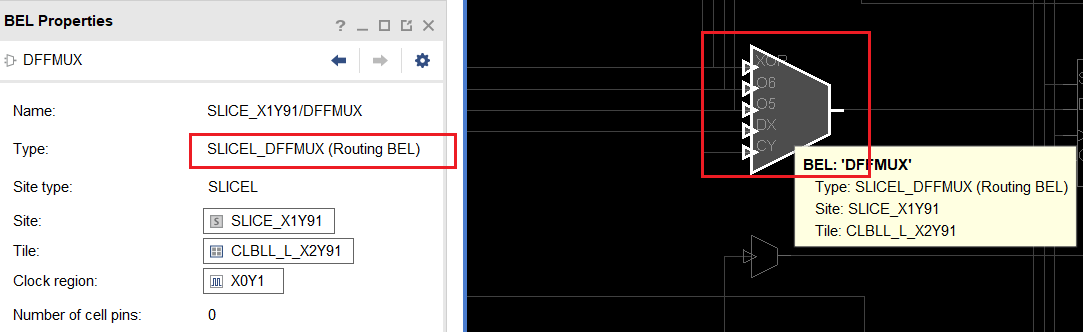
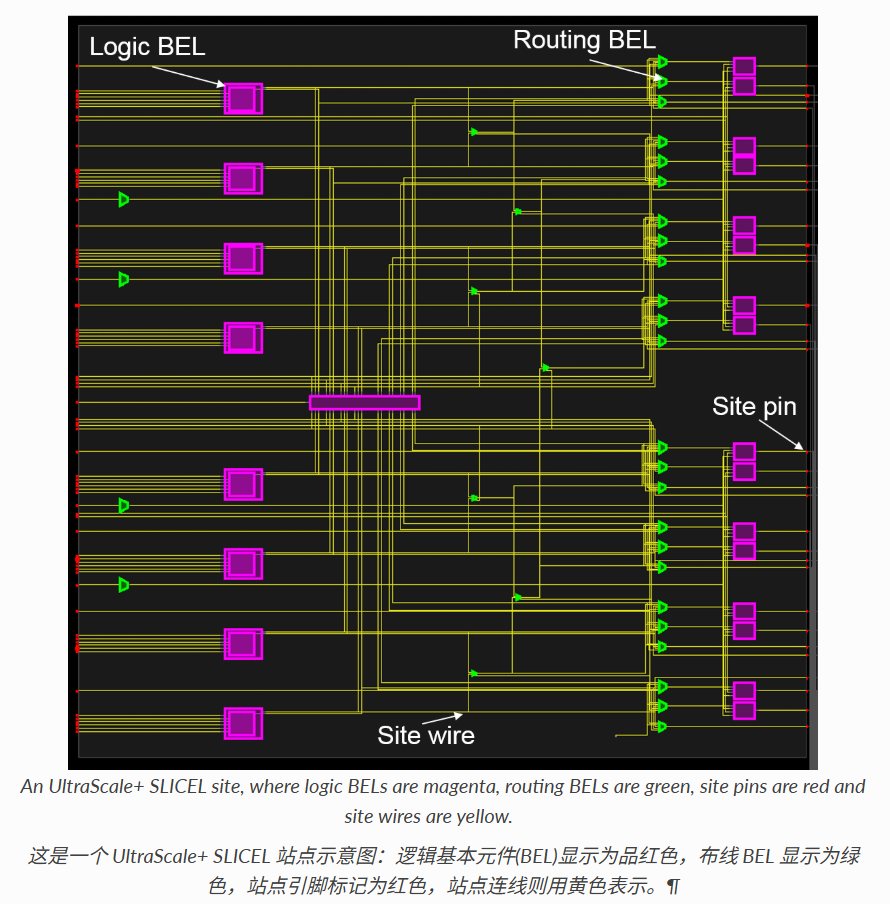
再放大一层,就进入了 Site 层级。最典型的 Site 就是 Slice——FPGA 逻辑结构的核心单元。每个 Slice 都有唯一名称(如 SLICE_X0Y0),内含 LUT、FF 等基本逻辑单元。
下面几张截图展示了在 Device View 中观察 Slice Site 的不同视角——从整体轮廓到内部细节:
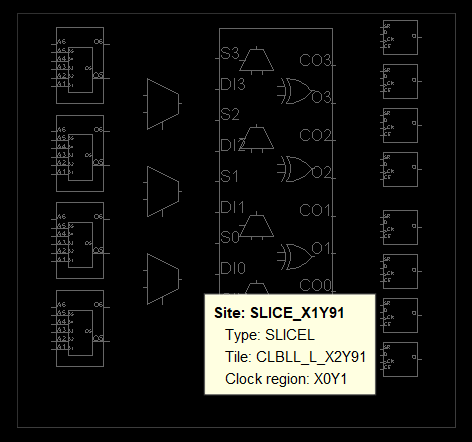
点击一个 Slice,可以在 Properties 面板中看到它的详细信息,包括类型(SLICEL/SLICEM)、坐标和内含的 BEL 列表:
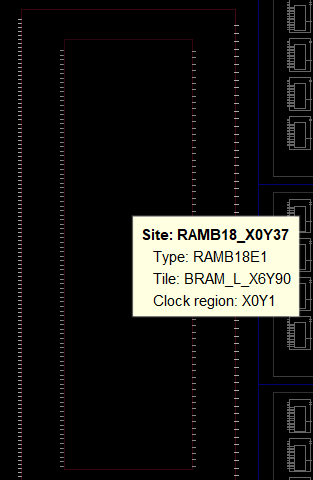
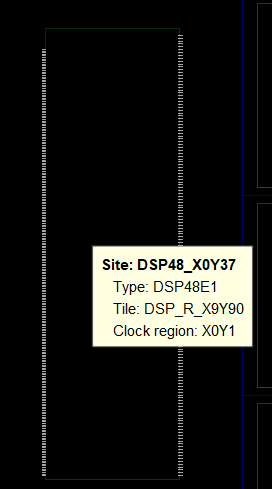
除了 Slice,硬核 IP 如 DSP48 模块和 BRAM(块 RAM)等专用资源也以 Site 形式存在,每个功能模块占据一个或多个 Site:
逻辑 BEL:最底层的功能单元
放大到最底层,就能看到 Slice 内部的每一个 BEL——触发器(FF)、进位链(CARRY4)和查找表(LUT)。这些直接实现逻辑功能和时序功能的基本单元,就是逻辑 BEL:
路由 BEL:隐藏的信号选择器
逻辑 BEL 之间还需要信号选择和转发,这就是路由 BEL 的工作。默认情况下路由 BEL 是隐藏的,需要在 Device View 中勾选 Routing Resource 选项:
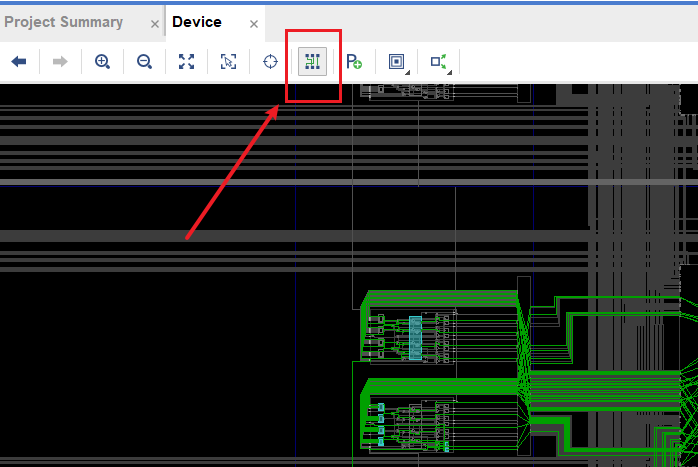
勾选后,视图中就会显示路由 BEL 的信息:
路由 BEL 不实现逻辑功能,而是在逻辑 BEL 之间选择信号路径。典型的例子包括:
- 触发器输入多路选择器(如 FFMUX)——决定 FF 的输入来自 LUT 输出还是旁路信号:

- 数据输出信号多路选择器(如 DOUTMUX)——选择 Site 输出的数据来源
我们以名为 ACY0 的路由 BEL 为例,深入分析它是如何工作的。点击它,查看输入输出信号:
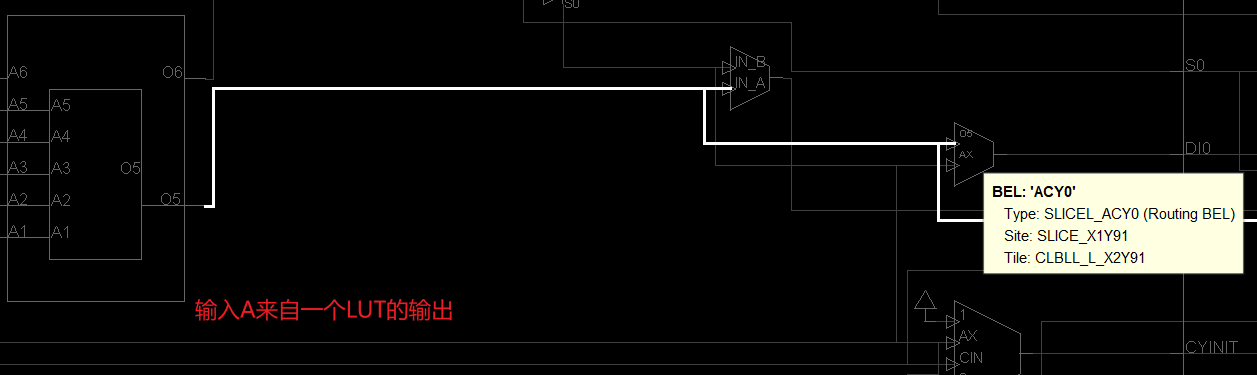
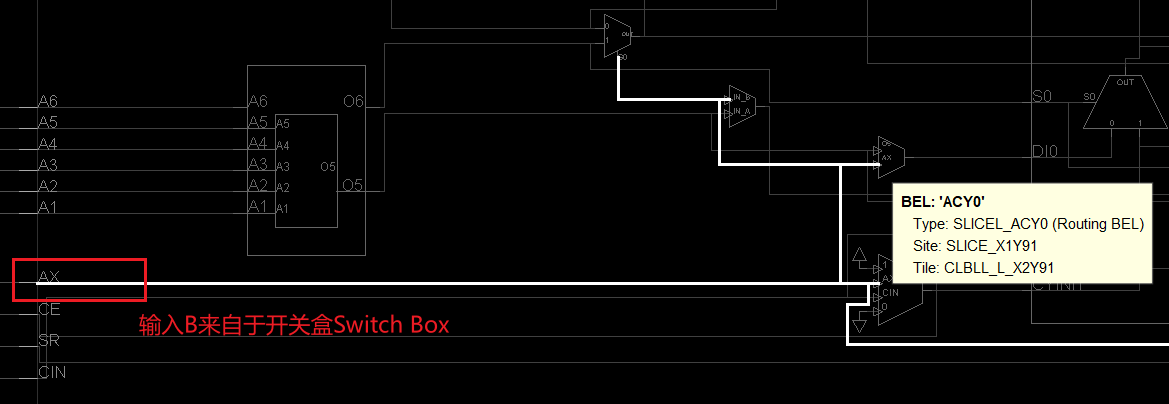
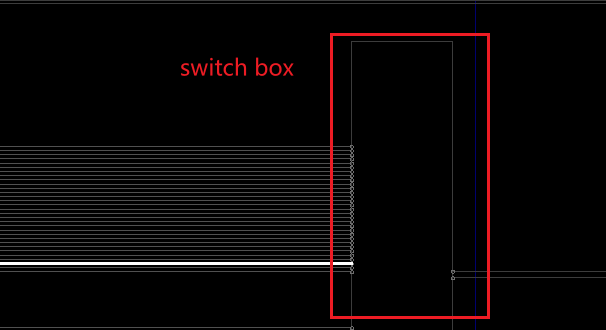
可以看到,ACY0 的某个输入端(如端口 B)连接到了开关矩阵(Switch Box)。Switch Box 相当于一个”信号中转站”,汇聚了附近各种资源的输出——可能是相邻 CLB 的 FF 输出,也可能是 LUT 输出,具体取决于实际的 RTL 代码和布线结果。正是路由 BEL 和开关矩阵的配合,才让 FPGA 底层资源之间实现了灵活互联。
设计映射:你的代码落在了哪里?
在实现(Implementation)完成后,Vivado 的 place_design 命令会将网表中的所有逻辑单元分配到兼容的 BEL 上。在 Device View 中可以直观地看到这个映射关系:
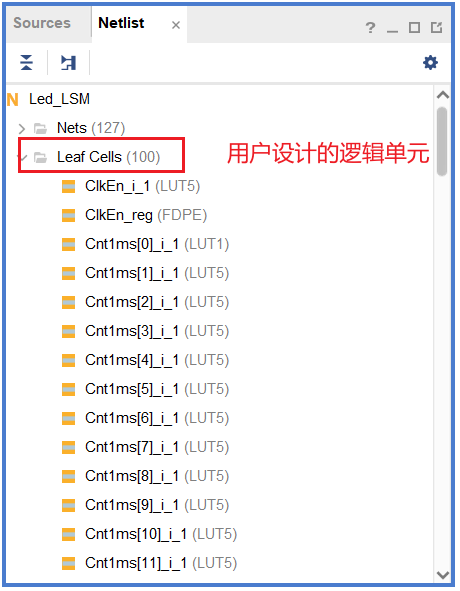
图中的 Leaf Cells 就是你设计中的逻辑单元。经过 place_design 阶段后,每个 Leaf Cell 都被放置到了一个具体的 BEL 上——这就是”你的 Verilog 代码最终变成了什么”的物理答案。
关键观察点
- 勾选 Routing Resource:可以看到路由 BEL(如 FFMUX、DOUTMUX)
- 查看 Properties 面板:点击任意资源,可以看到它的完整层次路径(如
SLICE_X12Y34/A6LUT) - Leaf Cells:在实现后的视图中,你能看到你的设计逻辑单元(Leaf Cells)被放置到了哪些具体的 BEL 上
💡 工程师手记:我建议每个 FPGA 初学者都花 30 分钟在 Vivado 的 Device View 里”漫游”一次。从全局缩放到 BEL 级别,点击各种资源看它们的属性。这比读十页文档更能建立对 FPGA 内部结构的直觉。
(建议替换为你自己探索 Vivado Device View 的经历)
10. 总结
| 层级 | 名称 | 一句话理解 | 你需要知道的一件事 |
|---|---|---|---|
| 第 1 级 | BEL | 最小功能单元(LUT、FF 等) | 你的代码最终映射到 BEL 上 |
| 第 2 级 | Site | BEL 的集合(如 Slice) | 每个 Site 有唯一的 _X#Y# 坐标 |
| 第 3 级 | Tile | Site + 本地互连(如 CLB) | 一个 CLB = 2 个 Slice |
| 第 4 级 | Clock Region | 共享时钟网络的区域 | 关键路径尽量不要跨 Clock Region |
| 第 5 级 | SLR | 一颗独立的硅片 Die | 小型 FPGA 可忽略,大型器件要注意跨 SLR 时序 |
| 第 6 级 | Device | 整颗 FPGA 芯片 | 器件型号决定了你的全部可用资源 |
理解这六级层次,就像拿到了一张 FPGA 的”行政区划图”。当你在 Vivado 中看到任何资源名称或坐标时,都能立刻定位它在芯片中的位置和角色。
下一篇文章,我们将深入 CLB 内部,看看 LUT、MUX 和 Carry Chain 是如何协同工作的。
常见问题
Q1:BEL 和 Site 的区别是什么?
BEL 是最小的功能单元(如一个 LUT、一个 FF),Site 是容纳 BEL 的物理位置(如一个 Slice)。一个 Site 里有多个 BEL,就像一个房间里有多件家具。
Q2:为什么 SLICEL 和 SLICEM 共享坐标网格,而其他 Site 类型不共享?
因为 SLICEL 和 SLICEM 在物理上占据相同的位置——一个 CLB 中的两个 Slice 位置,要么放 SLICEL,要么放 SLICEM。它们是同一种”房间”的两种”装修方案”,所以共用地址。
Q3:Clock Region 和 I/O Bank 是一一对应的吗?
不是。以
XC7A35T为例,它有 5 个 I/O Bank 但 6 个 Clock Region。Bank 是按 I/O 电压分组的,Clock Region 是按时钟分配网络划分的,两者的边界不一定重合。
Q4:跨 SLR 的信号延迟大概有多大?
具体数值取决于器件型号,但通常跨 SLR 的额外延迟在 0.5~1.5 ns 量级。对于高频设计(>300 MHz),这个延迟可能占据一个时钟周期的很大比例,需要在跨 SLR 路径上插入流水线寄存器。
参考资料
- Xilinx/AMD,UG474: 7 Series FPGAs Configurable Logic Block User Guide
- Xilinx/AMD,UG472: 7 Series FPGAs Clocking Resources User Guide
- Xilinx/AMD,UG904: Vivado Design Suite User Guide - Implementation
- CSDN,从底层结构开始学习FPGA(0)——FPGA的硬件架构层次
系列导航:本文是「FPGA 内部资源深度解析」系列第 1 篇。
如果这篇文章对你有帮助,欢迎点赞、收藏,也欢迎在评论区分享你在 Vivado Device View 中的发现。